The Base Layer Will Be Open

The Tell
On March 19, 2026, Cursor launched its Composer 2 model, calling it "coding intelligence at frontier level." Within a day, a developer inspecting API traffic spotted a model identifier: kimi-k2p5-rl-0317-s515-fast.
Cursor is a ~$50B AI company targeting ~$6B of revenue in 2026, and Composer 2 is the flagship of its product roadmap. Anthropic and OpenAI both have competing coding agent products in Claude Code and Codex, so it is paramount for Cursor to own its own models. And yet it did not train a whole new frontier model from scratch. Cursor started with Kimi K2.5, an open-weight model from Moonshot AI, post-trained with RL for coding.
Cursor's VP of developer education later confirmed it, somewhat awkwardly adding that "roughly a quarter of the training compute came from that base, the rest is our post-training."
It Is Cool To Be Closed
In terms of momentum, as measured in the attention economy, the gap between closed and open-weight models could not be more stark.
- In March 2026, Alibaba's Qwen team fell apart. Lin Junyang, the technical lead and the public face of Qwen globally, resigned abruptly. Yu Bowen, the head of post-training, left the same day. Hui Binyuan, the Qwen Code lead, had already gone to Meta in January. Three pillars of the team in ten weeks. The reporting suggests Alibaba is shifting toward consumer DAU metrics and horizontal, product-driven structure.
- Meta's Llama 4 was a dud. The company reportedly planned a pivot to closed proprietary models (codenamed Avocado and Mango) under new Chief AI Officer Alexandr Wang. It has since partially hedged, saying it'll release open versions of the next generation, but the frontier-open-by-default Meta of 2023–2024 is long gone.
- Ai2 lost Ali Farhadi, Hanna Hajishirzi, and Ranjay Krishna to Microsoft's Superintelligence team in March 2026. The Paul Allen-linked foundation that funds Ai2 is publicly pivoting toward applied AI over frontier open- model development.
Meanwhile our closed-model philosopher gods grace magazine covers.

No Jensen, but a shredded Demis Hassabis. That poor robot.
Green Shoots Sprouting Down the Stack
That Cursor is building on open weight is not an anomaly. A quick look at OpenRouter's top models over the past month shows that four out of the top five (and 12 of the top 20) most-used models are open weight.
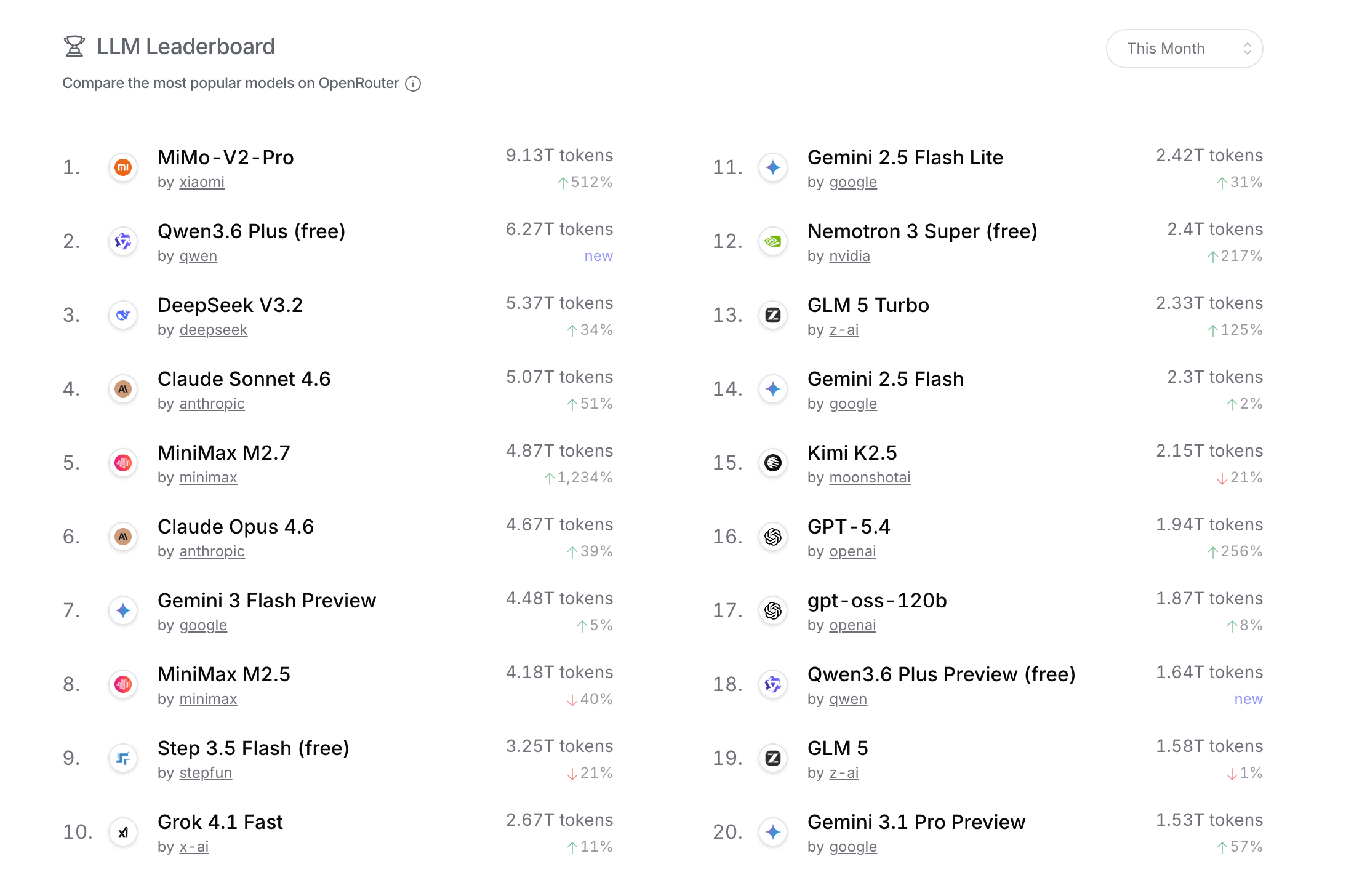
OpenRouter Top Models, snapshot taken April 21, 2026
The numbers above are not a measure of total AI inference market share, as they don't capture workloads generated from applications developed by OpenAI, Anthropic, or any other model developer that also builds its own applications. The tokens processed by ChatGPT, Claude Code, and Claude Cowork would undoubtedly dwarf the total tokens processed by OpenRouter.
However, the numbers above are an additional proof point that application builders are moving away from the frontier labs' hosted offerings towards building their own solutions on top of open-weight models. Increasingly, the stack looks like the following:
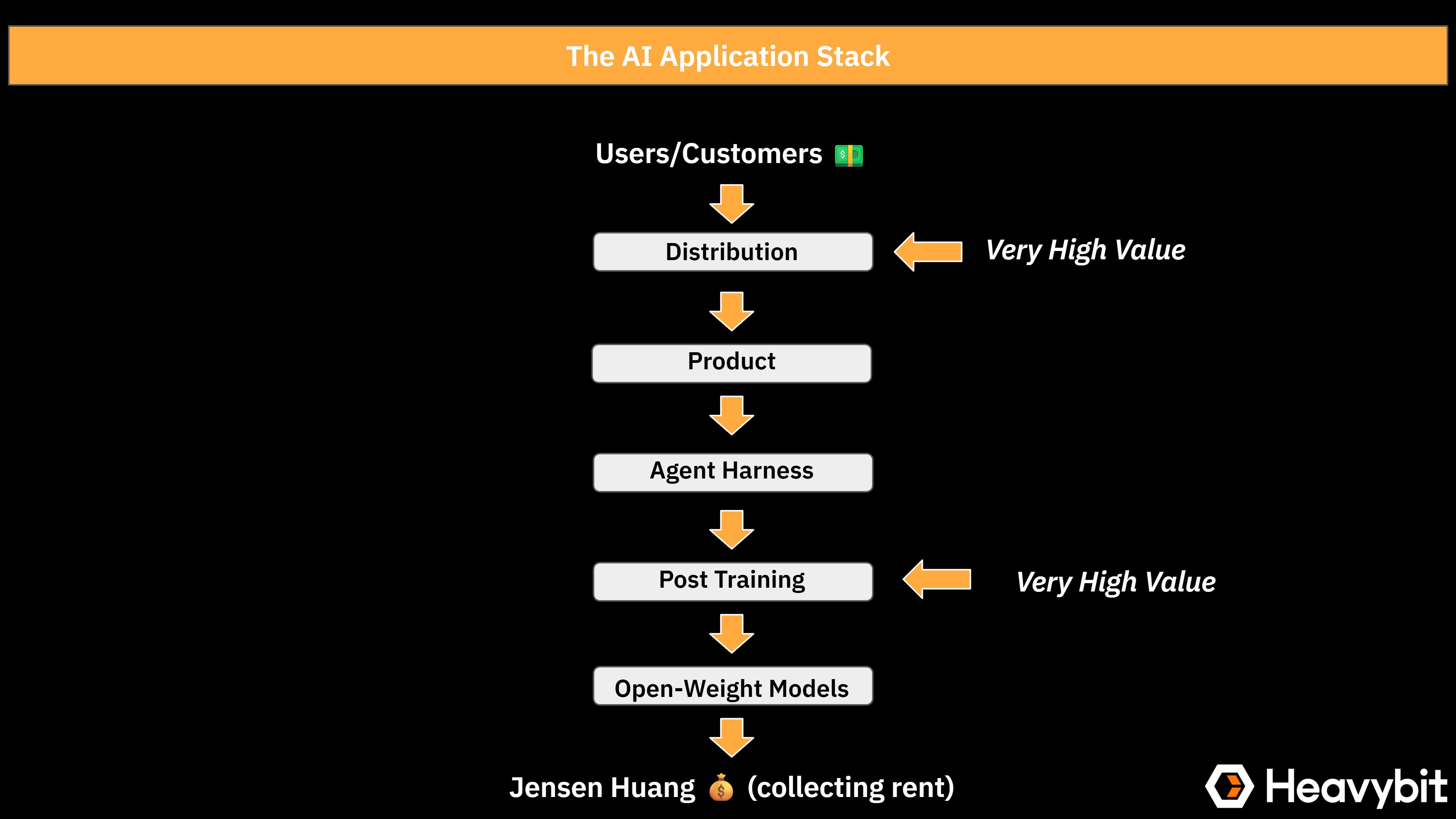
This emerging stack reflects the fact that the AI ecosystem is maturing.
Most AI applications need models that are good at the very specific tasks their product does. Cursor does not need a model that is good at physics and biology, it needs a model that can design, write, edit, and reason about code in a real repository with real tools quickly, accurately, and cheaply. That is a much narrower target than "frontier general intelligence." Cursor now has built up a dataset from real-world use over time which it can leverage to effectively post-train. Training a base model from scratch means paying to teach it basic reasoning and tool use all over again. Calling a frontier API means paying for superintelligence your product will never exercise. Taking an open base and RL'ing it on your corpus of coding data and environments is the option that spends compute where it actually matters.
Where Open Weights Are the Only Option
The post has focused on LLMs and application stacks built on top. It should be noted there are other areas, such as on-device language models or Physical AI, where the only options are open-weight models. I would argue this is the case because these markets are still very early, and for all the players any progress will help all the ships rise. As these ecosystems mature, we can expect dynamics similar to LLMs to take shape.
Who Will Pay to Develop Open Weight?
Training LLMs costs a lot of money, and the base models are still improving rapidly even if the pace of progress from pre-training is slowing. Releasing it and getting no API revenue from it is not a business. And yet the application layer described above is quietly being built on this infrastructure and somebody has to pay for it. In the US, the traditional answer was Meta, but the new answer is increasingly no one.
Meta is retreating, Ai2's backer is pivoting to applied AI, Mistral has gone into services. Chinese labs have jumped on this vacuum and used open-weight as a wedge for distribution. The Kimi family of models now has the best open- weight models available. But similar to Alibaba and Qwen, one can only assume most of them will lock up their frontier models over time.
The obvious US player with the means and motivation to bankroll open-weight model development indefinitely is Nvidia. Thankfully, at this year's GTC, it committed $26B to open- source model development. It has the compute resources. One can only hope it will bring on a team that can turn this investment into strong models with good distribution.
Parting Thoughts
Open-source software was declared dead many times. Yet today it powers most databases, operating systems, and web browsers in the world. LLMs will not be different. Open weights won't own the frontier of capability and headlines, but they will win at the base layer. Expect a lot of AI products not coming out of OpenAI, Anthropic, and Google over the next 24 months to quietly look a lot like Composer 2 under the hood. And if you are working on open-weight models in the US, my hat's off to you. You won't get a spot on the cover of The Economist. You will have to be content with powering a diverse AI application ecosystem.
Content from the Library
The Acqui-Hire Is No Longer a Distress Sale
Acqui-Hires Then Vs. Acqui-Hires Now Throughout startup history, an acqui-hire meant a company had failed. The product didn’t...
Can You Build a Company Around RL?
During a discussion earlier this week with a friend working on an RL engine at a major academic lab, he mentioned his strongly...
So You Want to Be an AI Engineer?
The "AI Engineer" job title is a recent invention, and companies are hiring a lot of them. I've generally assumed an AI engineer...