Can You Build a Company Around RL?

During a discussion earlier this week with a friend working on an RL engine at a major academic lab, he mentioned his strongly held belief that an "RL infra company” can never be a viable standalone business.
I was shocked: not only because of who was saying it, but also due to the mindshare and investor interest RL commands these days.
But he has a point. From ~50 companies on Madrona's market map from a couple years ago, only 4 are focused on model training. Of those, one (Mosaic) was acquired, one (Cerebras) is mainly a hardware company, and Together and Modular now bill themselves as inference providers.

So, is RL/post-training infrastructure a venture-scale category by itself? Or should we think of it as a feature for inference providers and a workflow for the makers of foundational models?
RL Is Already Big Business
Billions are already being spent on RL:
Mercor claimed to be at $500M of annual revenue in September 2025.
Databricks reports $1B of AI revenue which includes RL from their Mosaic acquisition.
Anthropic and OpenAI are pouring money into post-training and RL as pre-training hits scaling laws and we run out of human-generated text data.
If you attended the NeurIPS conference in San Diego in December 2025, you would have felt like AI==RL.
At the same time there is no single large infrastructure company that is focused on RL or post-training infrastructure. Unsloth and Prime Intellect are the only companies I'm aware of dedicated solely to post-training infra.
Training Is Hard. Inference Is Eas(ier)
Doing inference reliably at scale is not easy. GPUs are scarce, context windows are exploding, and managing KV caches at scale is real engineering work. But it is, fundamentally, an infrastructure problem, not a research problem.
There are open models, open inference stacks like SGLang and vLLM, optimized kernels, routing layers, and cloud abstractions. If you have capital and good engineers, you can stand up an inference service.
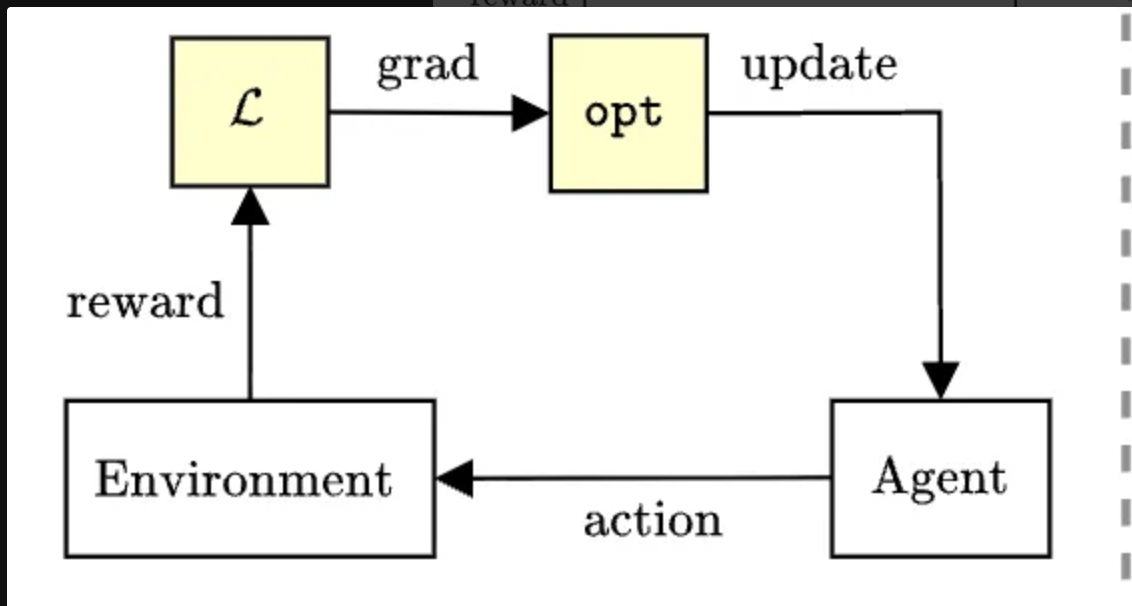
Training a model is a very different process than simply running inference.
Training is a different beast, and RL in particular is messy, unstable, and expensive. You are interacting with environments, defining reward functions, and fighting regressions. While in theory models now have enough base intelligence to do long-form white-collar work with RL-based post training, the bottlenecks to delivering this vision are not generalizable algorithms and infrastructure.
The Environment and Verification Bottleneck
The current consensus is that we can deliver autonomous agentic AI from our base models through post training with RL, and that the blockers to delivering these agents are synthesizing the environments that mimic long-horizon tasks and defining verification methodology needed to determine correctness on these tasks. As tasks being automated become longer and more complex, defining what “correct” means becomes unclear and needs deep domain expertise. Reinforcement learning depends on reward signals, but in real work those signals are ambiguous, gameable, and can shift in long-horizon multi-turn tasks. Software development was the first domain to which labs delivered autonomous long-horizon agents (i.e. Claude Code), and I believe this was because the people who worked at the labs are the domain experts in writing code, and verifying software correctness is fairly straightforward.
Bottlenecks present business opportunities, and there is already a growing market around the problem of RL environments and verification. Frontier labs are the earliest and most concentrated buyers of RL environments and companies like Mercor and Halluminate are positioning themselves upstream as suppliers of expert feedback, evaluation scaffolding, and environments.
Companies like Applied Compute (and some RL consulting shops) are taking another approach: Instead of asking enterprise workers and recent grads to moonlight and create RL gyms, they are going to enterprises directly and leveraging artifacts created by their workforce to build "autonomous workers" owned by the enterprise. This makes sense: If you are a large bank or hedge fund, in order to prevent Anthropic or OpenAI from cannibalizing your business, you should capture artifacts created by your workforce (docs, screens and mouse clicks) to train your own autonomous workforce.
So, Can You Build a Company Around RL?
Yes, but it won't look like inference.
The inference providers won because they solved an infrastructure problem: Serve models fast, reliably, and at scale. Capital and good engineering get you there. But a standalone RL business cannot win on speed or scalability alone. The bottleneck isn't infrastructure, it's the algorithms and the complex data pipelines needed to see value from them.
A viable RL company needs to deliver something fundamentally new: continual learning from on-policy RL. Any such service will need to:
- Include pipelines that synthesize RL environments from model outputs
- Automatically build (or at least propose) reward signals and verification
- Update model weights and biases in the background with little human intervention
Today, this is a research problem. Whoever solves it can create a generational company.
Content from the Library
Lab Notes Ep. #1, Why Robots Are Hard with Ren Wang
On this debut episode of Lab Notes, Amir Zohrenejad is joined by Ren Wang, a researcher and PhD student at UC Berkeley, to...
High Leverage Ep. #11, Why Agents Need Computers with David Crawshaw
On episode 11 of High Leverage, Joe Ruscio speaks with David Crawshaw about the shift from traditional developer infrastructure...
High Leverage Ep. #10, The Human Brain in Software Development with Steve Krouse
On episode 10 of High Leverage, Joe Ruscio sits down with Steve Krouse to discuss the rapidly evolving relationship between AI...