The Realities of Docker in Production
 Jérôme PetazzoniEnix
Jérôme PetazzoniEnix
Docker seems like a fundamentally better abstraction for packaging and deploying applications in a persistent way across multiple environments. Among individual developers and ops engineers it’s praised, but at a recent Docker in Production meetup held at Heavybit, engineers from Iron.io, ClusterHQ, RelateIQ and Docker discussed the realities of running Docker in Production — namely what does and doesn’t work.
What it’s All About
Docker’s roots are in the development world, where developers tend to run applications on a single machine. But the truth is that real apps run on more than one computer. Making this leap with Docker means paying attention to how you compose your production systems. According to event host Luke Marsden of ClusterHQ, there are four categories of obstacles you need to address when scaling from a single-host environment to multi-host environments:
- Composition: This requires being able to construct an application (or microservice) with multiple connected containers. This is often done with Fig, now called Docker Compose.
- Scheduling: This is about running across multiple machines, and choosing which machines to run containers on. It’s a critical component, along with composition, for running multi-container applications on multiple machines. Some common Docker schedulers include Fleet and Marathon.
- Networking: Networking in this case is how your containers talk to each other from different hosts, and how you know where your containers are—in essence, it’s service discovery. Solid networking is not yet an out-of-the-box stable experience for Docker users, though tools like Calico, Weave, and Flannel are providing network architecture for Docker containers.
- Storage: You can’t currently containerize and operationalize databases in containers, because when you attach a volume to a container, the server that container is on becomes too permanent—falling into the dreaded “pet” classification in the now never-going-to-die “pets vs. cattle” IT metaphor. Solutions like Flocker are looking to solve this problem.
But the puzzle pieces don’t quite fit…
While there are more than a few tools that have worked to flesh out the Docker ecosystem and make these central principles achievable, there is still a core issue: it’s not currently possible to compose all these different pieces together. The current shape of Docker systems look something like this:
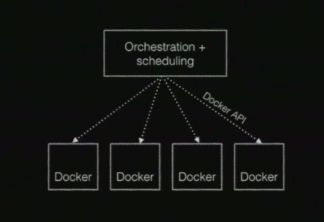
In this current model, there’s an orchestration component (Mesosphere, Swarm) using the Docker remote API to talk to Docker hosts, but networking and storage extensions have a big issue—they’d need to take on the role of orchestration as well. And it’s a pretty straightforward issue beyond that: wrapping sucks. Tools like Flocker and Weave have to have their own user experiences and command lines to meet their needs.
Marsden also spoke about how there needs to be a plugin mechanism in the Docker remote API that sits on top of Docker, and allows network and storage plugins to peacefully coexist. He says there are three things required to make this solution viable: these extensions need to be late-bound, composable, and optional. He suggests ClusterHQ’s Powerstrip as a composable adapter that meets these criteria. Powerstrip is a Docker API proxy that has multiple blocking pre-and-post hooks on arbitrary Docker API calls. This allows a Powerstrip proxy to load two Docker extensions side-by-side.
A separately echoed concern, from RelateIQ and Docker, has been that production environments shouldn’t include containerized persistent data stores.
This was mentioned earlier in the context of the “pets vs. cattle” metaphor. Docker says this is an example of something where they don’t want to do everything—they want to let the Docker ecosystem and community step in when they can do a better job. Though, in this particular instance, persistent data storage is something Docker would like to internalize in the future.
Accomplishments with Docker
At the event, Iron.io was quick to point out some of the benefits they’ve seen from implementing Docker in production. The company provides an event-driven compute service that uses Docker to provide flexible environments to use almost any language and version to perform on-demand async workload processing. These benefits have also been echoed by others including those who’ve gone on record as official Docker use cases. Iron.io’s list of positives included:
- It’s easy to update and maintain images – Docker’s image-layering system allows efficiency with images and managing dynamic environments.
- Improved resource allocation and analysis-Docker builds upon the capabilities of LXC-based containers with a REST API, version control, pushing/pulling images, and access to metric data.
- Easy integration with Dockerfiles-Clean images make it faster and more consistent to deploy and test with distributed, global teams.
- Quick growth and a strong community-Docker is updating all the time, and the level of community involvement in updates creates a helpful, positive, and knowledgeable environment.
Limitations with Docker
At the same time, Iron.io also documented some of their difficulties with Docker. Nevertheless, their pain points haven’t stopped them from using Docker in production at high scale – the company has run over 500M Docker containers since adopting it over year ago. Additionally, many of the difficulties with Docker are quickly becoming outdated by the rapid growth and stabilization of Docker updates. Currently, Iron.io’s pain points with Docker include:
- Limited backwards compatibility—Perhaps a symptom of their aggressive growth, they encountered occasions where syntax and output format changed between versions.
- The ecosystem is still a bit shaky—While the Docker ecosystem is on the whole a huge plus, keeping up with the collections of tools requires an enormous amount of knowledge and tinkering.
And while they had other pain points documented, such as long deletion times and volumes not unmounting, they quickly overcame those production obstacles. The general impression is that Docker’s feasibility in production grows stronger with every stable release, and the problems are generally outnumbered by the positive attributes.
Keeping an Eye on the Docker Roadmap
Looking at the Docker roadmap can help us get a better understanding of what issues Docker has identified and is looking to implement. Docker has always taken the stance that it doesn’t need to be everything — that it should allow a Docker ecosystem with solutions to flourish around it. You know when they start talking about new features, they’re very serious about them.
Docker’s Jérôme Petazzoni had a few words on the status of several high-profile Docker projects. Docker has always been up front about the uncertainty involved in some of these components; for example, even the documentation on Swarm and Machine warns that “[Docker] doesn’t recommend using [them] in production yet.” Of the projects, Compose is the most mature, and it rounds out the three projects in Docker’s aim to create a comprehensive set of orchestration services.
Conclusion
In addition to the above examples, we’ve heard about others using Docker in production, including New Relic and Spotify. Nevertheless, a great in-production experience is always a question of scalability and reliability between different teams and systems. The general impression is that, while there’s a lot you can do with Docker, there’s still plenty to be done.
For more Heavybit tech talks visit heavybit.com/library.
Subscribe to Heavybit Updates
You don’t have to build on your own. We help you stay ahead with the hottest resources, latest product updates, and top job opportunities from the community. Don’t miss out—subscribe now.
Content from the Library
The Kubelist Podcast Ep. #49, From Containers to Unikernels with Felipe Huici of Unikraft
On episode 49 of The Kubelist Podcast, Marc Campbell and Benjie De Groot sit down with Felipe Huici to explore how unikernels are...
Open Source Ready Ep. #24, Runtime for Agents with Ivan Burazin of Daytona
In episode 24 of Open Source Ready, Brian Douglas and John McBride sit down with Ivan Burazin, CEO of Daytona, to explore how his...
Open Source Ready Ep. #17, AI Native Software Factories with Solomon Hykes
In episode 17 of Open Source Ready, Brian and John speak with Docker founder Solomon Hykes about his latest project, Dagger, and...