RAG vs. Fine-Tuning: What Dev Teams Need to Know
 Kim Harrison
Kim Harrison
RAG vs. Fine-Tuning: Advantages and Disadvantages
In the rapidly evolving world of artificial intelligence, the ability of machine learning models to produce coherent, relevant responses has become critically important. Foundation models like GPT-4 or LLaMA have shown impressive question-answering capabilities, but they come with a limitation: Their knowledge is frozen at the time of training.
More Technical AI Resources:
- Video Compilation: How to Make Open-Source & Local LLMs Work in Practice
- Guide: LLM Fine-Tuning: A Guide for Engineering Teams in 2025
- Guide: Synthetic Data for AI: Purpose and Use Cases
- Guide: How to Create Data Pipelines
- Interview: How to Properly Scope and Evolve Data Pipelines
- Interview: Best Practices for Developing Data Pipelines in Regulated Spaces
For teams working with generative AI (GenAI), retrieval-augmented generation (RAG) is a powerful architectural innovation that overcomes this constraint by enabling real-time access to external knowledge sources using natural language processing (NLP). In simple terms, RAG can enhance a model’s performance allowing it to retrieve relevant data (beyond the general knowledge it may possess from prior training) dynamically from the appropriate data sources and incorporate it into generated responses.
Let’s break down how RAG works, what makes it valuable, what complexities are involved, and the tools organizations are using to adopt it successfully.
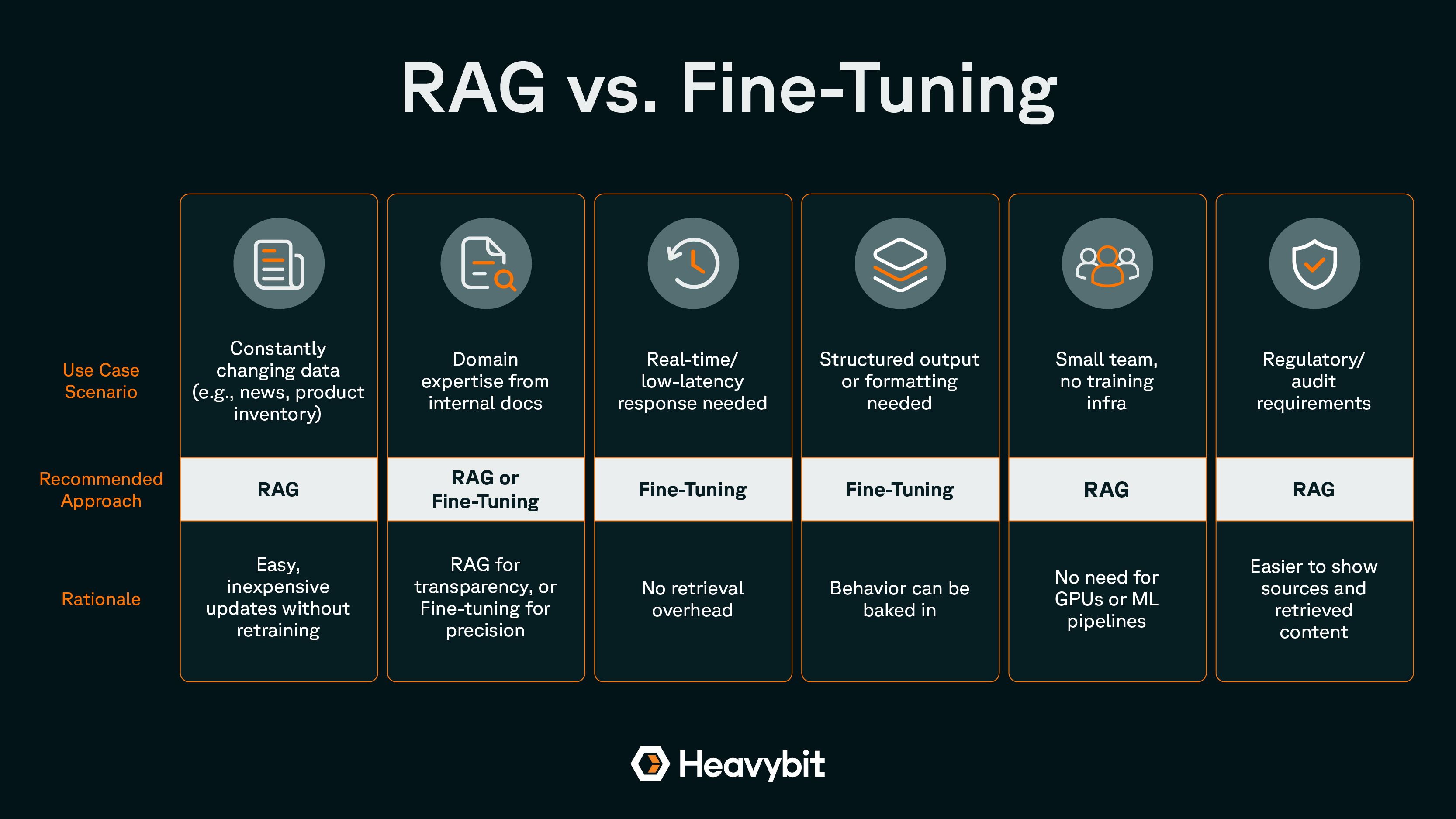
Different use cases may be better suited to RAG vs. fine-tuning.
What Is Retrieval-Augmented Generation (RAG)?
RAG is a technique that extends the power of machine learning models by combining them with a data retrieval system that can access external knowledge sources in real-time. Instead of relying solely on what was encoded during training, the RAG system can "look up" information from external data sources—like a vector store containing documents, articles, or enterprise data—before generating a response. RAG models effectively use ad hoc data retrieval to enhance a machine learning model’s performance.
This approach allows AI models to stay current, using ad hoc information retrieval to adapt to different domains and contexts. You can think of RAG as giving your AI a dynamic memory—one that can be updated anytime, queried efficiently, and used intelligently to improve outputs.
Without RAG, foundation models are like a closed-book: they only know what they were trained on. With RAG, they become an open-book: they can consult an external, always-updatable knowledge base as needed with domain-specific data.
How RAG Works: The High-Level Architecture
At a high level, a RAG pipeline consists of two main components: retriever and generator.
The retriever component searches a knowledge base to find the most relevant pieces of information (passages, documents, or snippets) based on the user’s query. Instead of full-text search, RAG systems typically use vector search—a method that finds semantically similar documents using embeddings generated by models like OpenAI's text-embedding-ada, SentenceTransformers, or Cohere.
Once the retriever returns relevant context, the language model (like GPT-4 or LLaMA) takes this context and the original query to generate a coherent and informed response. The generation is "augmented" with retrieved knowledge.
A defining trait of RAG is that knowledge is not stored inside the model’s parameters, but in a separate and often dynamic storage system—usually a vector database. This decouples knowledge from the model itself, which is a game-changer in terms of flexibility, cost, and maintainability.
Key Benefits of RAG
RAG unlocks several major advantages for teams working with large language models (LLMs):
Dynamic Knowledge UpdatesUnlike traditional LLMs that require costly retraining to learn new information, RAG systems can be updated on the fly with new data. Want your chatbot to understand today’s breaking news or a newly added product in your catalog? Just update the knowledge base, no model retraining necessary.
Lower Infrastructure Costs Compared to Fine-TuningThe fine-tuning process for large models is expensive in both computational resources and engineering effort. RAG allows you to avoid this by offloading domain-specific data and knowledge into a retrievable format. The base model remains unchanged, which saves time and money.
Easier to Iterate and DebugWith RAG, improving your system often means adjusting the data retrieval pipeline or curating better documents—processes that are faster and safer than altering a model’s weights. This makes development cycles shorter and more transparent.
Enhanced Factual Accuracy and TrustBecause RAG systems can cite their sources or refer to specific retrieved passages, the responses tend to be more grounded. This is essential for applications that require trust and traceability, like legal advisors, medical assistants, or customer support agents.
Domain-Specific CustomizationNeed a model to specialize in financial reports, technical documentation, or legal precedents? With RAG, you can tailor responses by simply controlling what data is stored in the information retrieval layer—no need for model-specific customization.
The Trade-Off: Added Complexity
While RAG systems are incredibly powerful, they introduce new layers of complexity compared to vanilla LLM applications. Some areas that should be given careful attention include:
Retrieval QualityThe performance of a RAG system hinges on its retriever. Poor retrieval leads to irrelevant or confusing context being passed to the generator, which degrades the quality of the response. Tuning retrieval involves selecting the right embedding models, refining the search index, and filtering results intelligently.
Vector DatabasesRAG typically relies on vector databases like Pinecone, Weaviate, Qdrant, or FAISS to store and search embeddings. These databases must be managed for performance, availability, and data freshness. Indexing strategies, vector dimensionality, and approximate nearest neighbor (ANN) algorithms all play a role.
Prompt EngineeringYou can’t just shove retrieved documents into a prompt and expect good results. Effective prompt engineering is critical–you need to decide how to format the retrieved content, where to place it in the prompt, how many documents to include, and how to structure the prompt to steer the model toward accurate, context-aware answers.
Evaluation and Feedback LoopsMeasuring the performance of a RAG system isn’t trivial. You need to monitor retrieval precision, generation quality, and hallucination rates. It often involves human-in-the-loop evaluation or advanced automatic scoring systems that blend search relevance with natural language understanding.
Popular Tools in the RAG Ecosystem
A growing number of open-source and commercial tools make it easier to build and deploy RAG systems. Here are some of the most widely used:
LangChain is a Python framework that simplifies building RAG pipelines by chaining together components like retrievers, vector stores, and LLMs. It offers abstractions for managing prompts, memory, agents, and retrieval workflows. It's especially popular for building chatbots and custom search agents.
LlamaIndex (formerly GPT Index) focuses on creating structured indices from unstructured data, making it easy to plug external data into LLM applications. It supports various vector databases and retrieval strategies and plays nicely with LangChain and other LLM frameworks.
Pinecone is a fully managed vector database that handles storage, indexing, and retrieval at scale. It’s known for high performance, ease of integration, and production-readiness. It supports metadata filtering and hybrid search (text + vector).
Weaviate is an open-source vector database with built-in support for semantic search, classification, and multi-modal data. It includes a GraphQL interface and allows for automatic schema inference, making it a strong choice for teams building custom knowledge systems.
FAISS, Qdrant, and Milvus are open-source options that provide robust alternatives to commercial vector databases. FAISS (by Meta) is a library for efficient similarity search, while Qdrant and Milvus offer full server-based vector storage with filtering and scale-out capabilities.
Compared to fine-tuning, RAG is potentially a faster, more up-to-date method of improving performance, but it’s not plug-and-play.
RAG represents a powerful shift in how we think about building intelligent systems. By decoupling knowledge from the model and allowing dynamic access to relevant information, RAG gives teams a flexible, cost-effective, and more accurate way to use generative AI in real-world applications.
However, adopting RAG is not a plug-and-play solution. It requires thoughtful design of the retrieval pipeline, selection of the right tools, careful prompt construction, and continuous monitoring to ensure relevance and reliability.
For teams building AI systems that need to reason over private data, stay current with external information, or deliver grounded answers with references, RAG is quickly becoming the gold standard architecture. As the ecosystem matures—with tools like LangChain, LlamaIndex, and Pinecone evolving rapidly—implementing RAG is becoming increasingly accessible and impactful.
What Is Fine-Tuning?
As organizations race to adopt LLMs for everything from chatbots to document analysis, a key question keeps coming up: How do we make these models work better for our data, use cases, and tone? One common answer is fine-tuning.
Fine-tuning is a powerful technique that customizes a pre-trained language model on a specific training dataset to achieve more precise, context-aware, or brand-aligned behavior. While alternatives like prompt engineering or RAG also aim to steer LLMs, fine-tuning offers a fundamentally different approach—changing the model itself, not just the inputs or supporting data.
Fine-tuning is the process of continuing to train a pretrained model on a new, typically smaller, training dataset that is specific to your domain or application. It’s like taking a general-purpose expert and teaching them a niche skill through focused practice.
To clarify how fine-tuning fits into the broader LLM development stack, let’s distinguish it from two related concepts: pretraining and prompt engineering.
Pretraining is the initial process of training a large model on a massive, diverse dataset of training data (like Common Crawl, Wikipedia, or books). This is where the model learns the structure of language, basic facts, and reasoning patterns. Pretraining is computationally expensive and only done by major AI labs.
Prompt engineering involves crafting instructions and examples in the input to guide model behavior. It’s a lightweight, zero-cost way to steer output but is limited in its ability to enforce consistent behavior or deep domain alignment.
Fine-tuning sits between these two extremes, offering more precision than prompting without the cost and scale of pretraining.
How Fine-Tuning Works: Custom Training on Target Data
At a high level, the fine-tuning process involves taking a pretrained model and continuing its training using a smaller, targeted dataset. The process of compiling training data typically includes the following steps:
Data Collection and CleaningThe first step is to collect a high-quality dataset that represents the task, tone, or domain you want to teach the model. This might include: customer service transcripts, medical case reports, legal contracts, internal documentation
Cleaning, labeling, and formatting the data (usually into input-output pairs) is critical to avoid introducing noise or bias.
Model SelectionYou then choose a base model. If you're working with open-weight models, you can download and fine-tune locally. If you're using a proprietary model, you’ll use the vendor's fine-tuning API.
Training the ModelTraining typically involves supervised learning, where the model adjusts its internal parameters to better predict the desired outputs given your inputs. Depending on your specific use case, you might also use reinforcement learning or instruction tuning.
Modern fine-tuning frameworks like LoRA (Low-Rank Adaptation) or QLoRA (Quantized LoRA) have made it easier and more memory-efficient to fine-tune large models on modest hardware.
Evaluation and TestingAfter training, you’ll evaluate the fine-tuned model to ensure it generalizes well to new examples. Metrics like accuracy, F1 score, BLEU score (for generation tasks), and human feedback are commonly used.
Open-Weight vs. Proprietary Models: Two Fine-Tuning Paths
Not all models can be fine-tuned the same way. The landscape splits into open-weight models and proprietary models, each with different implications for access, control, and cost.
Open-weight models are available for download and modification. You can fine-tune them on your own infrastructure or using cloud GPUs. This offers full control over the model and training process, which is ideal for teams with MLOps capabilities and strict privacy requirements.
On the other hand, proprietary models with fine-tuning APIs don’t expose their weights but offer APIs for uploading fine-tuning data. The provider handles the training process. A quick list of pros and cons:
Open-Weight Models
Pros and cons for open-weight models like the META LlaMA families, Mistral, Falcon, BLOOM, or Pythia:
Pros:
- Full control over weights and architecture
- No vendor lock-in
- On-prem deployment possible
Cons:
- Requires infrastructure and ML engineering expertise
- More complex to scale and manage
Proprietary Models with Fine-Tuning APIs
Pros and cons for proprietary models with fine-tuning APIs like ChatGPT, Claude, Cohere, AI21, or Google PaLM:
Pros:
- No need to manage infrastructure
- Easy to use with minimal ML expertise
- Automatically integrates with hosted inference APIs
Cons:
- Limited flexibility in architecture and customization
- Potential vendor lock-in
- Higher long-term cost for high-usage applications
Key Benefits of Fine-Tuning
Fine-tuning isn’t the right tool for every situation, but it shines in use cases where precision, control, and integration are critical.
Precise Behavioral ControlPrompt engineering can only go so far in steering output. Fine-tuning lets you bake in the exact tone, structure, and policy adherence you need—whether that’s avoiding disclaimers, matching brand voice, or using specific formatting.
Deep Domain AdaptationLLMs are trained on broad data, which can be weak or inaccurate in niche areas like biomedical research or legal reasoning. Fine-tuning allows the model to internalize deep, domain-specific knowledge that isn’t easily accessible via RAG or prompting.
Tighter Workflow IntegrationFor enterprise software that relies on deterministic behaviors (e.g., filling forms, structured output, or specific taxonomy usage), fine-tuning provides a way to hardwire patterns into the model’s behavior.
Multi-Turn or Task-Specific MasteryIf your use case involves multi-turn dialogue, classification, summarization, or code generation, fine-tuning can make the model more adept at handling those specific tasks.
Fine-tuning is more resource-intensive than RAG, but offers potentially better response times and gives users more control over output formats.
The Challenges of Fine-Tuning
Fine-tuning offers great power that can enable LLMs to grasp deeper nuances in complex fields like healthcare, but it comes with significant challenges—especially when compared to lighter-weight methods like RAG or prompting. (It can also be a more time-consuming approach to improving your model’s performance.)
High Cost and Compute RequirementsTraining large models—even for a few epochs—requires significant GPU time and memory. While adapter-based methods like LoRA can reduce cost, fine-tuning remains more expensive than prompt engineering or RAG. Introducing new data generally incurs high retraining costs.
Model Versioning and Lifecycle ManagementOnce you fine-tune a model, you create a new version that must be versioned, monitored, and maintained. This introduces lifecycle management complexity: Which version are we using in production? What data was it trained on? How do we roll back?
Risk of Overfitting or DriftIf your training data is too small or too biased, the model can overfit—losing its general-purpose abilities and hallucinating facts. Fine-tuned models can also "drift" from expected behavior over time if not retrained or evaluated continuously.
Evaluation Is HarderPrompt-based systems are easier to debug—you can tweak the prompt and re-run. Fine-tuned models are black boxes with learned behavior that’s harder to explain or adjust without retraining.
MLOps and Deployment ComplexityFine-tuning introduces classic ML deployment challenges: reproducibility, monitoring, rollback mechanisms, and model registry. Enterprises adopting fine-tuning often need mature MLOps pipelines to manage this complexity at scale.
Fine-tuning is a high-impact tool in the LLM toolkit, especially for organizations seeking precise, repeatable, and domain-specialized AI behavior. It offers more control and customization than prompt engineering and is ideal when RAG can’t capture the depth of domain expertise required.
But it’s not a silver bullet. Fine-tuning introduces infrastructure and lifecycle challenges that demand careful planning and evaluation. For many use cases, RAG or prompting may be sufficient and cheaper. The best approach often combines methods—using prompt engineering for flexibility, RAG for dynamic knowledge, and fine-tuning for precision and domain depth.
As LLMs continue to evolve, expect fine-tuning methods to become cheaper, faster, and more efficient—especially with innovations in parameter-efficient fine-tuning, quantization, and automated evaluation. But for now, teams should approach fine-tuning with clear goals, strong datasets, and the right tooling in place.
RAG vs. Fine-Tuning: Key Technical Differences
As LLMs become essential tools for enterprise AI, product personalization, and task automation, two strategies have emerged as the primary ways to adapt these models to specific domains: RAG and Fine-Tuning.
While both aim to improve accuracy, relevance, and utility, they do so in fundamentally different ways—with distinct architectures, performance profiles, and infrastructure needs. Understanding these differences is crucial for choosing the right approach for your use case.
Architecture and Data Flow
RAG
In RAG, the system consists of three main components:
- Retriever: Given a query, it fetches relevant documents or chunks from a vector database using semantic similarity (embedding search).
- Knowledge Store: An external, updatable source of truth (e.g., docs, articles, proprietary data) stored as embeddings.
- Generator: An LLM that takes both the user’s query and retrieved context to generate accurate responses.
This modular architecture separates the LLM from the data it relies on. Updates to knowledge don’t require retraining the model—just refreshing the content in the vector store.
Fine Tuning
In fine-tuning, you take a pre-trained base model and continue training it on a domain-specific dataset. The model learns to embed that new information directly into its weights. Once fine-tuned, all responses are generated from this internalized knowledge.
There is no retrieval component or external database—everything the model knows must be learned during training. How RAG and fine-tuning differ:
RAG:
- Updating data: Potentially instantaneous via vector database
- Adding new knowledge: Relatively easy with dynamic document ingestion
- Traceability: High with citable context
Fine-Tuning
- Updating data: Requires retraining
- Adding new knowledge: Must create new dataset and retrain
- Traceability: Low as responses may be less explainable
RAG offers far more flexibility and auditability, which is a major reason it's favored in fast-changing domains like legal, finance, or customer support.
Performance and Latency
Speed and responsiveness are critical for real-time applications, especially those deployed in production or embedded in user-facing apps.
Fine-Tuning: Low-Latency InferenceFine-tuned models are essentially “pure” inference engines. Once deployed, they require no external calls to retrieve information. This means:
- Lower latency: Responses are generated quickly.
- Better for streaming and real-time chat: Great for voice assistants, live coding tools, etc.
For example, a customer support chatbot trained on support logs via fine-tuning can answer quickly, making it suitable for high-throughput environments.
RAG: Additional Latency from Retrieval StepsRAG introduces at least one extra step: querying a vector database to fetch relevant documents before generating a response. This adds:
- Overhead from semantic search
- Latency from embedding generation (if done at runtime)
- Complexity from context formatting and token limits
Even small delays can affect UX in real-time apps.
Latency Mitigation Strategies for RAGTo combat this, teams use:
- Caching: Store previous retrieval results or final outputs based on query similarity.
- Asynchronous retrieval: Begin document fetch while processing initial user input.
- Index optimization: Use fast approximate nearest neighbor (ANN) search algorithms like HNSW.
- Client-side embedding: Pre-compute query embeddings to avoid runtime delays.
RAG users may observe higher inference latency due to the combination of both retrieval and generation; have caching opportunities in both the retrieval and prompt output steps; and may observe lower token efficiency due to including full context.
Fine-tuning users may see lower inference latency (having to only use inference for generation); have fewer caching opportunities at the prompt output step only; but see higher token efficiency due to pretraining.
Choosing between fine-tuning and RAG can come down to your resources, your customers’ expectations, and your regulatory environment.
Infrastructure and Tooling
Both RAG and fine-tuning require significant tooling, but the nature of the stack is very different.
RAG Infrastructure: Modular ML + Search StackRAG relies on a hybrid architecture that integrates language models with search infrastructure. Typical components include:
- Vector database (e.g., Pinecone, Weaviate, Qdrant)
- Embedding models (e.g., OpenAI, Cohere, SentenceTransformers)
- Retrieval orchestration (e.g., LangChain, LlamaIndex)
- Prompt templating for context formatting
- Chunking strategies for indexing long documents
RAG’s complexity lies in retrieval quality, chunking strategy, and prompt formatting—not model training.
RAG is ideal for teams that want fast updates to data, high transparency, and minimal training infrastructure.
Fine-Tuning Infrastructure: ML Training PipelinesFine-tuning requires a more traditional ML training stack:
- GPU compute for training and inference
- Data pipeline for cleaning, formatting, and labeling
- Training frameworks (like Hugging Face Transformers, PEFT, LoRA)
- Model hosting platforms (like Replicate, Sagemaker, Vertex AI, Modal)
- Version control for models and datasets
Fine-tuning introduces MLOps challenges including versioning models and datasets, managing fine-tuning artifacts, evaluating and validating outputs, and handling model rollback. A comparison of infrastructure elements when using RAG vs. fine-tuning:
RAG
- Core resources: Vector database, embedding models, LLM inference
- Skill requirements: Search, embeddings, prompt design
- How to Manage Updates: Can happen in real time via database
- Tool examples: LangChain, LlamaIndex, Pinecone, Weaviate
- Operational overhead: Moderate (retrieval tuning, prompt management)
Fine-Tuning
- Core resources: GPUs for training, datasets, model hosting
- Skill requirements: ML engineering, training optimization
- How to Manage Updates: Retraining needed
- Tool examples: Hugging Face, LoRA, OpenAI/Anthropic APIs
- Operational overhead: High (MLOps, model lifecycle management)
How to Choose the Right Approach for Your Use Case
There’s no one-size-fits-all answer—RAG and fine-tuning serve different needs.
RAG and fine-tuning are not mutually exclusive—in fact, many production systems combine the two. A hybrid approach might use RAG to inject current data into prompts, while fine-tuning ensures that outputs are formatted, styled, or filtered in specific ways.
Understanding the technical trade-offs between these approaches is essential for building scalable, maintainable, and performant AI systems. Fine-tuning gives you surgical control over how a model behaves, but requires serious infrastructure and MLOps support. RAG gives you agility and explainability, but introduces retrieval latency and retrieval engineering complexity.
For teams building next-gen applications, the best solution is often not either/or, but when and how to use both together.
Questions to Ask Before You Decide
Before jumping into implementation, consider these four key questions to frame your decision:
1. Is your data frequently changing or relatively static?RAG excels when your knowledge base updates frequently—product catalogs, pricing, policies, customer support FAQs.
Fine-tuning is better if the core knowledge is stable—like legal definitions, scientific terminology, or internal classifications.
2. Do you need precise, tightly-controlled outputs?Use fine-tuning when consistent tone, formatting, or behavior is required (like structured summaries or form outputs).
Use RAG when flexibility is more important than rigid control.
3. What infrastructure and talent do you have in-house?RAG requires experience with vector databases, prompt engineering, and search tuning—but not GPU training.
Fine-tuning requires ML engineers, model versioning, and MLOps pipelines.
4. Are latency or cost primary concerns?Fine-tuned models tend to be faster at inference, ideal for real-time systems.
RAG introduces retrieval overhead and may require more tokens, affecting cost.
Use Case Fit: RAG vs. Fine-Tuning
Here are practical examples where each approach shines:
When RAG Works Best
- Customer support bots: Pulls from up-to-date documentation, product info, or service logs.
- Internal search and chatbots: Integrates with company wikis, handbooks, or internal portals.
- Knowledge assistants: Summarizing legal contracts, scientific papers, or research reports.
- Compliance review tools: Cross-checks against evolving regulations.
When Fine-Tuning Works Best
- Classification tasks: Spam detection, sentiment analysis, document type labeling.
- Form parsing and structuring: Extracting data into predefined formats (e.g., CRM fields).
- Tone-specific writing: Generating content in a brand’s voice or for a specific persona.
- Code generation: When outputs must follow specific patterns or conform to style guides.
Hybrid Approaches: Can You Combine Both?
Sometimes, the best solution blends both worlds. Hybrid architectures combine the dynamic power of RAG with the precision of fine-tuning—though this adds significant complexity. Some examples of hybrid patterns include:
- Fine-tuned retrievers: Train a custom model to improve document selection in a RAG system.
- Fine-tuned generators: Use RAG to retrieve context, then pass it to a fine-tuned LLM that specializes in response formatting or tone.
- Layered workflows: Use RAG for knowledge injection and follow with a fine-tuned model for post-processing (e.g., structure, validation, or filtering).
Hybrid makes sense when your use case demands both freshness and structure (like a regulatory chatbot that references policy but formats output for legal review). Perhaps you’ve outgrown prompting and retrieval tuning but still need flexible data updates. Or you have MLOps maturity and the engineering bandwidth to handle dual pipelines and monitoring.
It’s important to proceed with caution. Hybrid systems introduce multi-point failure risk, require cross-discipline skills, and increase debugging complexity. For early-stage teams, this can slow iteration and introduce maintenance debt unless the use case truly demands it.
Choosing between RAG and fine-tuning isn’t just a technical choice—it’s a strategic one. It depends on how often your data changes, how much control you need, what infrastructure you have, and what your users expect.
Here’s a simple way to frame your decision:
- Use RAG when your knowledge needs to stay current and traceable.
- Use fine-tuning when your behavior needs to be consistent, structured, or domain-specialized.
Explore hybrid models only if your system requires both agility and deep model control—and your team is ready to support that complexity. Ultimately, the goal isn’t to pick a perfect approach—it’s to choose the one that best matches your real-world constraints while leaving room to evolve.
Content from the Library
Lab Notes Ep. #3, Exploring Recursive Intelligence with Qizheng Zhang
On episode 3 of Lab Notes, Amir Zohrenejad sits down with Qizheng Zhang to explore one of the fastest-moving areas of AI...
How AEO/GEO Differs from SEO (and Whether It Matters)
Does AEO/GEO Matter More or Less than SEO? It’s easy to find many deeply unhelpful statistics about the changing state of...