Three Key Best Practices for Modern Incident Response
 Andrew ParkEditorial Lead, Heavybit
Andrew ParkEditorial Lead, Heavybit
Incident management refers to the process that a company takes to detect, act upon, and resolve issues with their software products, particularly issues that cause process or customer issues, as well as follow-up actions to prevent future issues.
Learn more about the latest best practices and technology to maximize uptime and master the entire incident management process at the virtual DevGuild: Incident Response Summit.
What to Know About the Modern Incident Management Process
In the past, many organizations used to consider adopting incident management practices after the fact. Teams would “discover” site reliability engineering after the many support tickets, after the stressful process of trying to track down and triage breakages, and after the loss of goodwill and trust among customers. Estimates suggest that outages can cost companies as much as $300,000 per hour.
In a worst-case scenario, high-severity outages seem like every engineering team’s worst nightmare. They can be expensive and incredibly disruptive events that can take an entire team off course. Almost 40% of organizations have experienced a major outage caused by human error - and 85% of those incidents involved process breakdowns where teams either didn’t follow their plan or didn’t have one in the first place. At worst, severe outages can also do irreparable damage to a team’s relationships, morale, and ability to get things done in the future.
But incidents don’t have to be painful or costly, and you can train your team to become much better at managing them. Here are three key best practices from some of the most experienced voices in modern incident management.
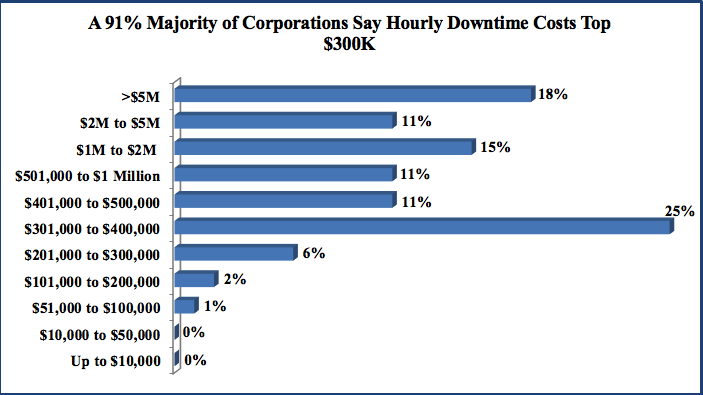
Downtime can cost organizations in excess of $300,000 per hour. Image courtesy TechChannel.
1. Normalize Incidents. Talk About Them Often.
One of the best ways to flip the script on incidents being terrifying, hidden dangers is to accept them as normal, inevitable parts of the development and deployment process.
Get people in a room that are impacted by incidents and have them talk about the impact. Figure out ways to work together differently. Modern orgs seem afraid to even use the term ‘incident.’ OK, but do you have things that interrupt your day? Things you’re afraid might go down? Because they’re impacting your team. Any work that gets impacted, that was unplanned, should be looked at.” -Nora Jones, Founder / Jeli
Nora Jones, the founder of Jeli and the Learning From Incidents community, points out that one of the most subtle but potentially significant obstacles to mastering incident management is approach avoidance. Busy engineering teams understandably prefer to focus their time on executing their current projects, but as a result, may end up avoiding proactive incident prep until it’s too late.
“Incidents touch many different areas of an organization,” says Jones. “Many people carry other stories. Discussing incidents doesn’t just help you prepare for them in the future - it helps you understand more about your team’s world.”
For Jones, engineering teams that accept incidents as a fact of life prepare themselves emotionally as well as organizationally. “Instead of seeing incidents as catastrophic, they’ll be a normal part of work. It’s not that you’ll suddenly have fewer incidents, but it will feel easier, less stressful, and more seamless. More importantly, you’re in a much better position to get the right people in the room faster and build more customer trust.”
While it can take some time to adjust, teams that shift their thinking and their approach will ultimately benefit. “It’s like building up muscle memory, and not just for individual engineers, but group muscle memory,” Jones explains. “Instead of hoping that the one superhero from the last incident can bail you out again, you’re making sure your whole team is prepared.”
2. Get Honest About Your Infrastructure. And Prepare Accordingly.
Developing modern, cloud-native software products offers many well-known benefits, including scalability, flexibility, and cost-effectiveness. One not-so-obvious downside is how many components of cloud-native software are owned and operated by third-party vendors, outside of your own engineering org’s control. Recent studies suggest that more than 50% of engineering teams don’t believe the public cloud is capable of managing all their mission-critical workloads.
One thing that’s often overlooked is taking dependency availability into account when setting SLAs. You may have services you depend on that offer four nines...but that doesn’t mean your systems will have the same. When you introduce dependencies you don’t control, the math changes. If each cloud dependency has their 0.01% downtime at a different time, your system simply cannot offer four nines itself.” -Jeff Martens / CEO, Co-Founder / Metrist
Metrist co-founders Jeff Martens (CEO) and Ryan Duffield (CTO) believe that engineering teams will benefit from a reality check on their infrastructure. Says Martens, “It’s very common for companies to have more than 130 cloud dependencies - third-party cloud apps that are a core part of their operational infrastructure.”
Because so much is riding on third-party applications, it’s crucial to understand the apps that underpin your org’s own software, as well as what the expectations are concerning uptime and response times. Martens explains: “Of course, developers understand that their orgs rely on mainstream platforms such as AWS and Stripe, but there are many more apps that provide foundational support for their operations. What they may not understand is the nature of each of their dependencies. What part(s) of my product do they power? What kind of functionality and uptime are they promising via their SLA? And just as importantly, how have they been performing against their SLA?”
Duffield adds: “A shocking number of services don’t offer an SLA at all. So to protect your software’s uptime, and your customers, it’s time to start having conversations with your vendors. Sure, maybe the conversation involves upgrading to a costly higher tier that may not be feasible right now. But it’s important to at least understand the historical and current performance of each of your services, especially if you’re relying on them every day for your own operations.”
“And the final part of actionability: Once you’ve figured out the things that are important, have an alternative provider as a fallback, pay for it, and practice switching to the fallback,” Duffield advises. “In case of emergencies, you’ll know how the process works. It’ll save you tons of time and money during outages when every moment counts.”
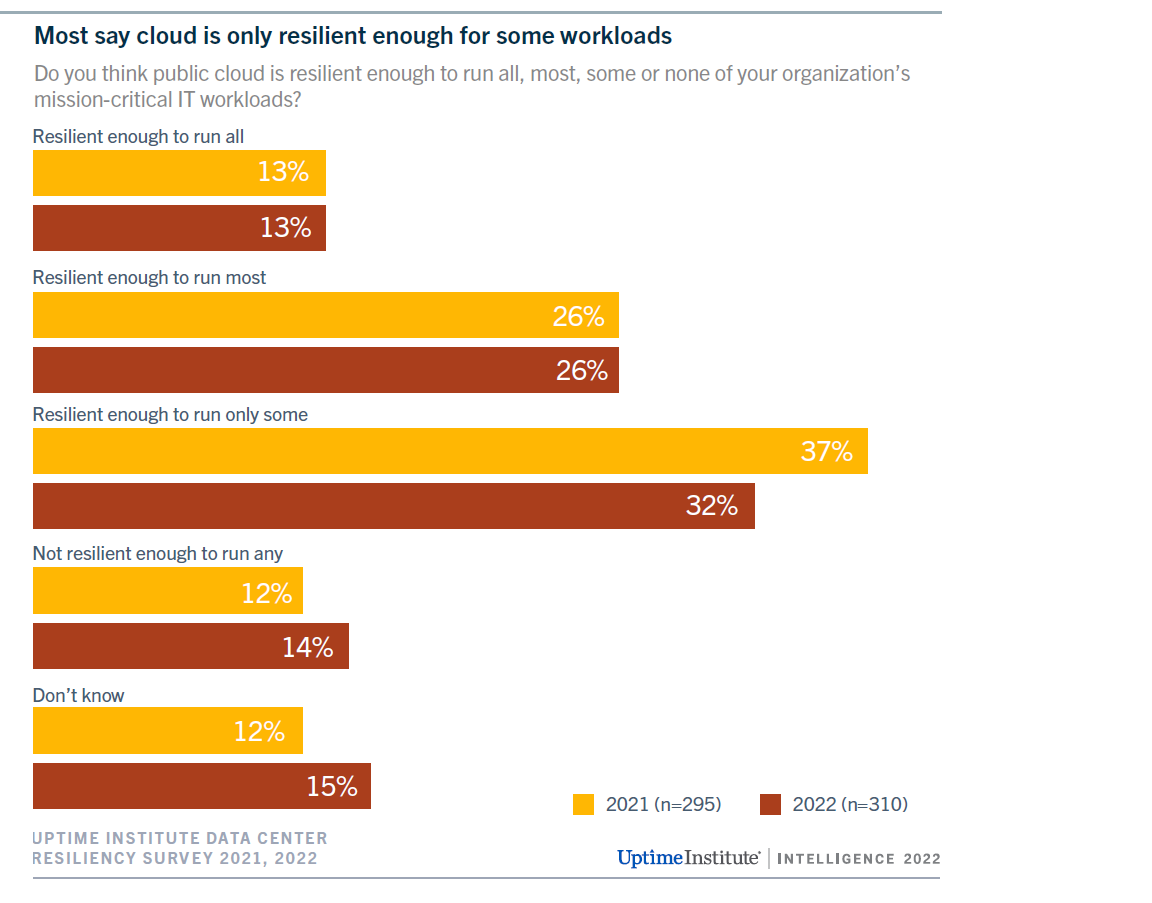
More than 50% of organizations feel the public cloud isn’t resilient enough to handle all mission-critical workloads. Image courtesy Uptime Institute.
3. Embrace the Process. Mastery Will Come.
Here’s the thing: I don’t know the difference between ‘observability’ and ‘incident management.’ When we talk about monitoring, DevSecOps...all these pieces are important. It’s time to start viewing incident management more broadly as a lifecycle. Engineering teams will get good at this when they embrace the whole process and each of its steps.” -Jesse Robbins, General Partner / Heavybit
Recent years have brought exciting new technical developments in important incident response processes, such as observability and monitoring. Heavybit general partner and Chef founder Jesse Robbins points out: “While early detection is extremely important, it’s one step in a larger lifecycle process of monitoring, detecting, understanding, responding, analyzing, and resolving. Observability is really important and there are some very exciting developments in the field right now, but it’s not a one-and-done. Obviously, once you find an issue, you have to then go put out the fire.”
Robbins points out that since so many outages are due to process-related human error, a key step to improving your engineering org’s incident management is better overall processes in combination with better tools. “I think it’s helpful to frame this whole concept of an incident lifecycle as a continuous circle, where we’re not just addressing today’s incident, but we’re also learning from it and preparing for future incidents.
Learn about the full incident management lifecycle and how your engineering team can become experts at incident response at the virtual DevGuild: Incident Management Summit.
Subscribe to Heavybit Updates
You don’t have to build on your own. We help you stay ahead with the hottest resources, latest product updates, and top job opportunities from the community. Don’t miss out—subscribe now.
Content from the Library
Incident Response and DevOps in the Age of Generative AI
How Does Generative AI Work With Incident Response? Software continues to eat the world, as more dev teams depend on third-party...
Getting There Ep. #7, The March 2023 Datadog Outage with Laura de Vesine
In episode 7 of Getting There, Nora and Niall speak with Laura de Vesine of Datadog. Laura shares a unique perspective on the...
O11ycast Ep. #59, Learning From Incidents with Laura Maguire of Jeli
In episode 59 of o11ycast, Jess and Martin speak with Laura Maguire of Jeli and Nick Travaglini of Honeycomb. They unpack...