Pillars of Success: What You Can Learn From Treasure Data’s Major Exit

Now that the news is finally public, we’re ecstatic to congratulate Heavybit member Treasure Data on their acquisition by ARM. Founders Hironobu Yoshikawa, Kazuki Ohta, and Sadayuki Furuhashi have built an amazing company that anchors Arm’s foray into IoT with the Arm Pelion IoT Platform. While financial terms of the transaction were not disclosed, it is one of the largest exits by a Heavybit company to-date and joins a recent string of other meaningful exits in the broader developer and enterprise “deep tech” ecosystem, including AppDynamics, CoreOS, GitHub, and Duo Security.
As a fellow Heavybit program founder myself, I’ve been fortunate to work alongside the Treasure Data team from its earliest days. Treasure Data had just graduated from the Heavybit program when my company, Librato, entered, and they soon became one of Librato’s earliest customers. Since hearing about the impending deal, I’ve been reflecting on their origins and identified a few key success factors to serve as inspiration for our other founders.
I’ll illustrate them with some slides from this 2013 keynote presentation when Treasure Data was just two years old. It demonstrates just how early in their evolution as a company they had these essential factors nailed down. In no particular order:
Build a Solution
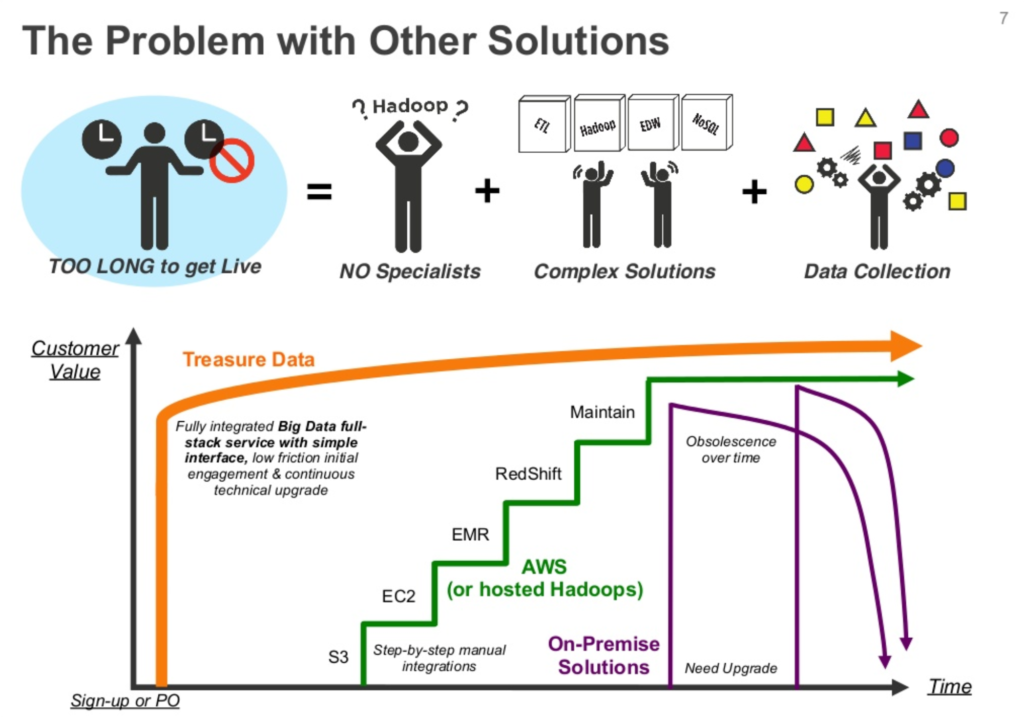
When Treasure Data was founded, the Hadoop ecosystem was ~5 years into a massive disruption of the traditional data warehousing market. Data volumes were exploding and legacy solutions were struggling to keep up – not to mention prohibitively expensive to procure, install, and maintain. Hadoop promised horizontal scaling on commodity hardware and the ability to start with the free, community-supported OSS. This soon led to the emergence of commercialized providers like HortonWorks and Cloudera. But while Hadoop addressed many legacy vendor shortcomings, it was still difficult to operate in production. You typically needed access to bare metal somewhere and in-house Hadoop expertise was required to reach any significant scale.
The Treasure Data team could have easily built some variant of Hadoop-on-Cloud and realized moderate success. However, they wisely chose to address the underlying problem the customer was really looking to solve, and created an ideal solution from first principles.
Their customers needed to integrate data from a vast array of sources, perform complex analytics, and spend as little time as possible on operation and maintenance.
Treasure Data built out a cloud-hosted solution that solved this problem end-to-end.
Ease of Integration
It’s fairly obvious in 2018 that modern enterprises use an ever-increasing mix of software tools to run their businesses. In this reality, integration is key, and companies like Slack, Segment, Datadog, etc. have proven that offering out-of-the-box integrations not only significantly reduce time to value, but also serve as a defensible moat. The Treasure Data team understood back in 2011 that the number of data sources in the enterprise was exploding and only going to increase. A more traditional vendor would solve this problem with professional services, charging customers for a set of manual integrations during onboarding.
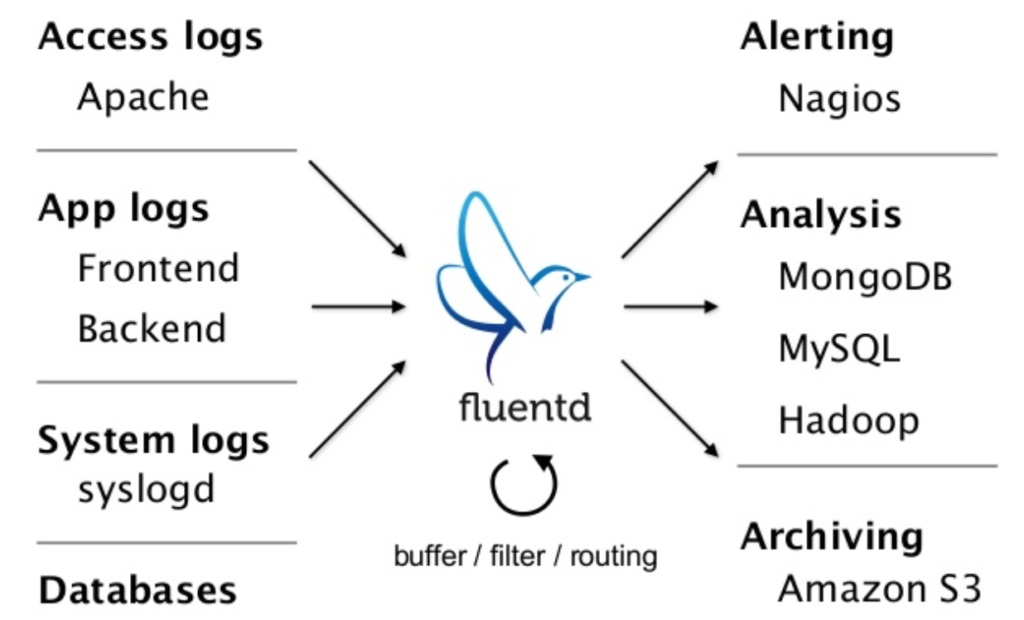
Treasure Data instead considered integrations a first-class problem that would persist throughout the lifecycle as an increasingly agile customer base continuously brought in new sources of data. They created an elegant software solution in FluentD, a scalable and extensible mechanism to gather real-time data from multiple sources, normalize it, and publish to multiple targets. It comes out-of-the-box with support for a huge number of sources/targets and its pluggable architecture ensures customers can easily add support for proprietary or esoteric sources.
Well Executed OSS Strategy
Treasure Data also made the decision very early on to open-source FluentD. The decision of how to open-source a key part of your value proposition is always a tricky one. Go too far and you’re left with support and services as your only viable business model. Conversely if the open-source version is too restricted you’ll fail to garner the adoption necessary to build a thriving community around it.
Treasure Data chose to bifurcate along the service boundary i.e. open source FluentD and its integrations but keep the cloud-hosted parts proprietary. This is a natural split that reduces barriers to adoption by addressing fears of vendor lock in and operating black-box agents. It increases the number of integrations (a key benefit noted above) as customers or even non-paying FluentD users are able to write and contribute plugins back to the community. It raises awareness amongst and provides beachheads into potential customers.
The team maximized this effect by making the Treasure Data integration itself a plugin on equal footing with all the other supported plugins. There’s nothing unnatural about using FluentD as standalone tooling and choosing to upgrade and connect to Treasure Data with a simple plugin installation at some future time. I believe that once conceived, this level of commitment to the OSS strategy enabled FluentD’s adoption by both Docker and the CNCF, which has led to wider spread adoption of FluentD than the founders could have ever envisioned.
These are assuredly only a handful of the factors that played into Treasure Data’s success over the last seven years, but I think they are the most applicable to the next generation of enterprise startups.
Build a complete solution that solves a fundamental problem for the customer. Ensure it integrates as simply as possible with their existing tooling. When leveraging OSS as a strategy, think carefully about how you can provide real, lasting value to the community while still preserving your ability to monetize. The Treasure Data team nailed all three and this fantastic outcome for them is well-deserved.
Subscribe to Heavybit Updates
Subscribe for regular updates about our developer-first content and events, job openings, and advisory opportunities.
Content from the Library
MLOps vs. Eng: Misaligned Incentives and Failure to Launch?
Failure to Launch: The Challenges of Getting ML Models into Prod Machine learning is a subset of AI–the practice of using...
Technical & Cultural Learnings from 10 Years of Computing
What the Software Community Has Learned from 10 Years in Tech Amara’s Law states, “We tend to overestimate the effect of a...
How to Generate Financial Reporting for Board Meetings
How to Get Financial KPIs Ready for the Board Meeting Your startup just closed its first major round after a long and arduous...